There are many ways to scan, this is the current state of the art in Calafou. We use only free software and the documentation is for Debian GNU/Linux, but it should work with some small modifications on any UNIX based system running the bash shell. There are some parts where proprietary software such as ABBYY FineReader can be more effective. However, this workflow produces near perfect books in PDF format that we are very happy with. One thing we could definitely improve is the size of the final PDF file, which is quite big (can be more than 100 megabytes).
The amount of work in the postproduction phase depends on how good quality images you can make in the scanning phase!
Setting up the cameras (calibration): the most important part.
open the book in the middle (at a central page with normal text on both sides)
camera should look directly on the middle of the page, parallel to the cradle, at 45 degrees compared to horizontal.
If you want to use the button to make the cameras trigger automatically, you must lock the SD cards before putting them in. Also, plug the many USB cables in.
check all x, y and z angles.
all the page should be in the image, but it is not a problem if more things outside of the book are visible
check if the pages fold/curve; if so, place something underneath to straighten it (like a sponge, or another book…)
camera settings: fully automatic, perhaps with manual focus
back up and empty the SD cards in the cameras
most subtle mistake: one camera sees letters bigger than the other camera (this can be a difference in the zoom level or the distance between camera and page)
use a post-it or similar to mark the exact position of the book in relation to the lower edge of the cradle, to ensure it remains in the same position throughout the scanning
Push the big button on the scanner to scan.
maybe you have to put your finger to the side of the plexiglass which is closer to you when it is “down”, because the plexiglass is not always exactly the same angle as the book pages
TURN OFF THE CAMERAS BEFORE REMOVING THE SD CARDS! (otherwise, pics will be erased!)
Download the images from the SD cards and put the scanner to sleep.
from the camera on the left, copy the images to a folder called “odd”
from the camera on the right, copy the images to a folder called “even”
remember to delete the pictures from the SD cards and put them back to the cameras, and maybe put the camera batteries to charge
Additional information using the marron_scanner 😎
Check before starting that the SD card are locked: the external trigger that controls the cameras requires the SD cards to be locked. If they are not locked, the pictures are not saved when using the external trigger.
Camera settings: we use two IXUS 175 set to automatic with menu/lamp setting set to "off" to avoid the use of the red light.
While taking pictures, if you need to check the last picture taken: long press the green play button to enter slideshow mode, long press the green play button to go back to picture mode (half pressure on the camera trigger also works)
If you decide to use the zoom of the camera (not the digital zoom), be careful not to turn off the camera or you will loose your zoom setting
Dependencies
Using an up-to-date Debian operating system, you can install the following programs for the postproduction steps:
scantailor
gprename
pdftk
tesseract-ocr
tesseract-ocr-eng
tesseract-ocr-spa
calibre
You can install all these programs with the following invocation from the command line (also called the terminal):
Some users may not find pdftk in the repositories. An alternative is pdfshuffler, which has a graphical user interface
Postproduction
You start with two folders such as odd and even with files like IMG_1234.JPG. It is not good to talk about right and left because it can be very confusing: are you talking about the image from the right camera that takes pictures of the left page of the book, or the image of the left page of the book that is from the right camera? On the other hand, odd (1, 3, 5, …) and even (2, 4, 6, …) are good words for describing what is on the image without ambiguity!
The basic workflow is like this:
[process] → [program] → [output]
Merge pictures from the two cameras → gprename → 1.jpg, 2.jpg, …
Edit the pictures to adjust contents → scantailor → 1.tif, 2.tif, …
Character recognition → tesseract → 1.pdf, 2.pdf, …
to rename the files properly, place .JPG in the "After the number" section above.
WHAT'S THIS ??? -> FIXME we can probably write a script to rename the files properly…
??? does it just talk about the .JPG in the step above?
scantailor
You can edit the captures appropriately with scantailor. It invites you to follow these steps:
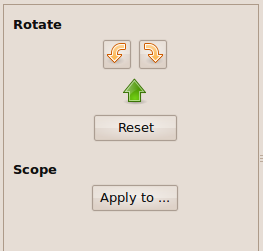
1st step: Fix orientation. All odd pages need to be turned in one direction, while even pages need to be turned in the other direction.
Rotate image nr 1 and click on "apply to every other page". Then select image nr 2, rotate in the opposite direction so it stays still, and also click on "apply to every other page".
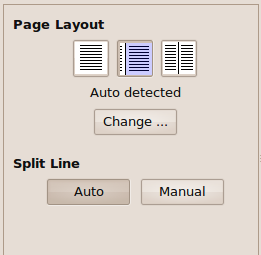
2nd step: Split pages. If you import all files renamed, odd and even pages will be recognized as single pages, so this step is just to confirm that the edges of the pages are set properly; drag the rectangles to fit in the page's area.
4th step: Select content. Frame all elements to be shown as content, within one single area (beware of including for example page numbers). The outer limit of these margins affects the size of the output file.
6th step: Output. Consider the visibility/readability of pages with images and/or mixed img-txt, managing the thickness slider. Check every tab on the column that emerged on the right:
- Picture Zones: use the tool to select areas with photographs, illustrations or special icons.
- Dewarping: manage the grid to stregthen your page's content.
- Desplekling: remove dust and dots from the page.









{kind=link}
{kind=link}